一、引言
在大数据和云原生时代,数据孤岛和异构数据源的整合成为企业数字化转型的核心挑战。
Apache Calcite 作为一个开源的动态数据管理框架,通过提供标准 SQL 解析、查询优化和跨数据源适配能力,为企业构建统一的数据查询层提供了关键支撑。
Calcite有意地远离了存储和处理数据的任务。如我们所见,这使得它成为在应用程序和一个或多个数据存储位置和数据处理引擎之间的最佳中间层选择。它同样也是构建数据库的完美基础选择: 只需要在它的基础上添加数据。
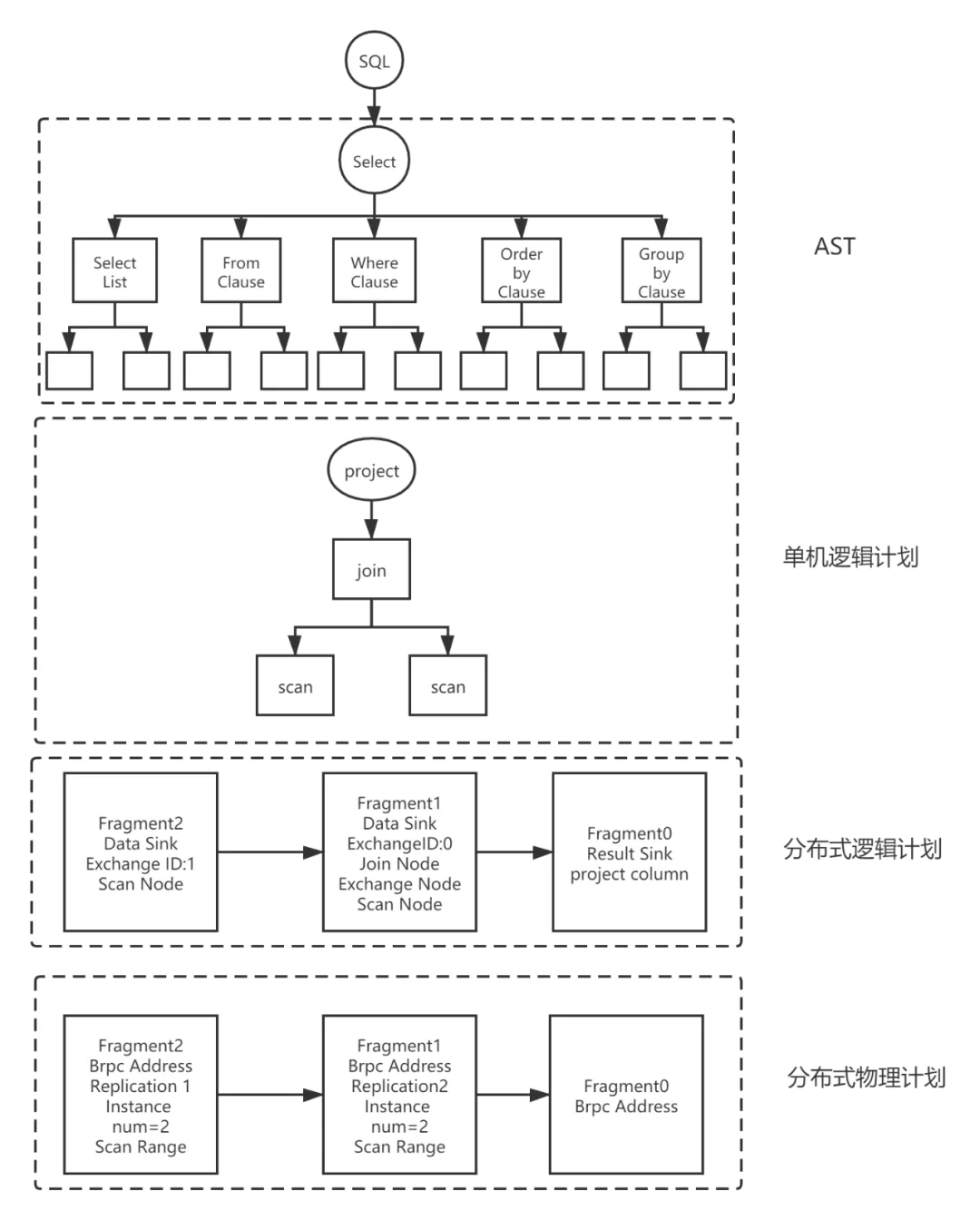
二、核心架构与技术特性
架构全景图
2025/4/18大约 4 分钟